Visão de produto
11 de February, 2021Strategy and objectives
15 de February, 2021In 2015, we decided to extinguish the Quality Assurance (QA) function of our Locaweb product development team. We had 12 QAs, some with a developer profile and others with a SysAdmin profile. In proposing the extinction of the QA role, some of the QAs became devs, while others took on the role of system administrators. The reasons that led us to extinguish Locaweb’s QA function were:
- When there is a QA function separate from the software development function, it is common to hear phrases like “the functionality is ready, now it is in the QA phase”, which denotes a cascading product development culture. This culture can considerably increase development time and negatively affect the quality of the software.
- When there is a QA function separate from the software development function, it is also common to hear phrases like “why didn’t QA detect this bug?”, Which denotes a culture of finding the culprits. This culture can be very detrimental to the engagement and motivation of the team and, consequently, negatively impact the quality of the software.
- Quality should not be the concern of a person or team, it should be the concern of everyone working on creating the software.
- Quality is a non-functional requirement, that is, it specifies a criterion to evaluate the functioning of a digital product, while a functional requirement specifies a behavior of the software. Performance, scalability, operability, monitorability are some examples of non-functional software requirements that are just as important as quality. Even so, there are no defined functions to guarantee performance, guarantee scalability, guarantee operability and guarantee monitorability. Why is quality the only non-functional requirement that has a specific dedicated function to guarantee it?
- Quality control focuses on ensuring the quality of the software development process. If a separate function is needed to guarantee this quality, why is there no need for a separate function to guarantee the quality of the product management process, the design process, the product marketing process, the sales process, the finance processof a company?
- There was a concern that, if the engineer himself now had to test, deliveries would take longer to be ready. This concern existed because the engineers considered that their work was finished – and the delivery was ready – when they passed the story to the QA to test. However, the engineer’s definition of ready is incorrect, as he has just passed the story on to the next phase, the test. From the user’s point of view, the story is only ready when the user can use the new feature. Therefore, the time that the delivery remains in quality control is still development time, even though it is no longer in the hands of the engineer. And that time gets even longer when the story goes through quality control, but it is rejected and needs to go back to engineering.
When I joined the Conta Azul, they had also just extinguished the role of QA, and the ex-QAs became business analysts, mainly helping product managers.
I saw other companies also discussing the need for QAs, and in some cases, a heated debate emerges around this topic. However, having or not having QAs should not be the focus of the discussion. Having or not having this function is the solution to a problem, usually referred to as “how can we improve the quality of our product?”, And that problem should be the center of the discussion.
How can we improve the quality of our product?
A simple Google search for software quality will yield tons of definitions typically related to meeting functional and non-functional requirements. When the software does not meet a functional or non-functional requirement, it has a defect, a bug. Therefore, to improve the quality of a software product, we need to work on two things:
- reducing existing bugs;
- not generating new bugs.
A good way to track this is to have a weekly measurement of your bug inventory and new bug creation per week and discuss this every week with the team. We did that at Gympass. We define at the beginning of each quarter what the target is for the bug inventory and the average new bugs per week.
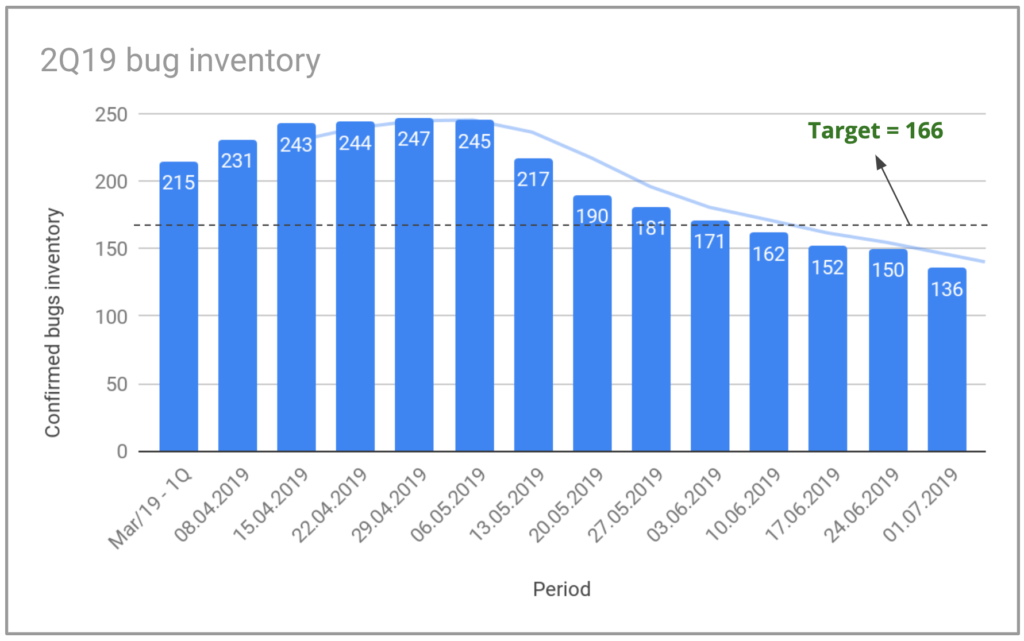
The image shows the evolution of our bug inventory during the 2nd quarter of 2019. We started the quarter with 215 bugs in our stock and we aimed for a target of less than 166 at the end of the quarter, a reduction of almost 23%. We ended the quarter with an inventory of 136 bugs, a reduction of 36%. We did this by focusing not only on resolving bugs in our inventory, but also on controlling the number of new bugs per week.
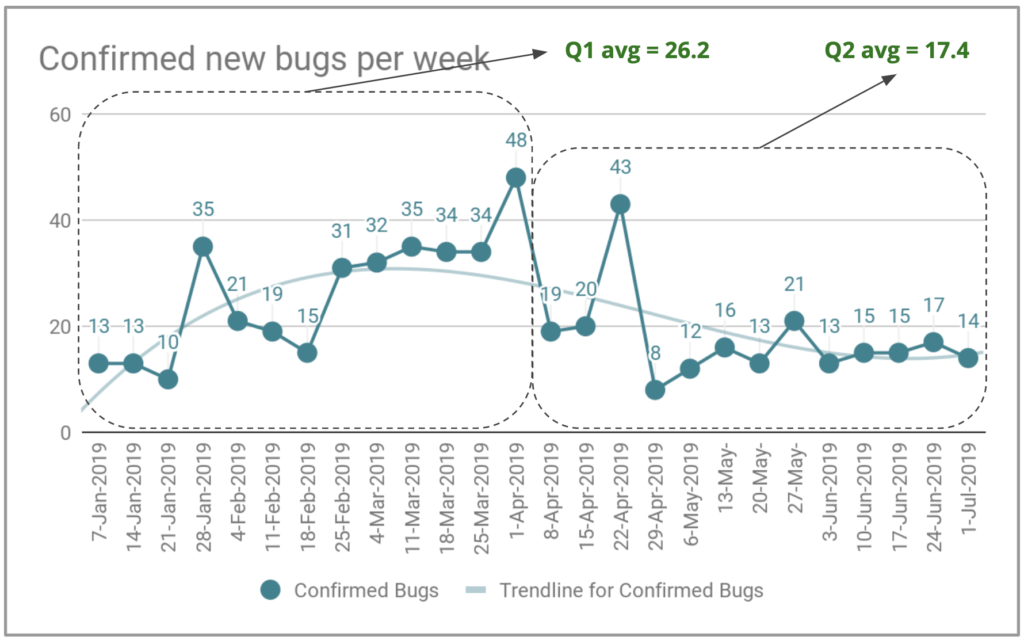
In the first quarter of 2019, we had an average of 26.2 bugs created per week. During the second quarter, we reduced this average to 17.4 new bugs per week, to a total of 226 new bugs during the quarter. This is a 33% reduction in the number of new bugs per week.
That looks like a pretty good improvement, right? But there is a lot of room for improvement there. Let me explain the math of bug management:
If we were able to reduce our bug stock from 215 to 136, it means that we have resolved at least 79 bugs. However, we created 226 new bugs (17.4 new bugs per week x 13 weeks) during the quarter. So we solved 79 + 226 = 305 bugs during the quarter, a lot of bug fixing work. If we had generated 90 new bugs during the quarter, an average of 6.9 new bugs per week, instead of the 226 new bugs, we could have zeroed out on the bug inventory.
An additional aspect of the bug resolution to be measured is the SLA (Service Level Agreement) resolution, that is, how many days the team took to resolve a bug from the day the bug was first identified. For this, we classify the bugs by their severity, which is the impact it has on users and the business. The most serious bugs are those that we need to resolve on the same day; high severity errors, in 7 days and average severity, in 14 days. The following chart shows how we were at Gympass in the fourth quarter of 2019.
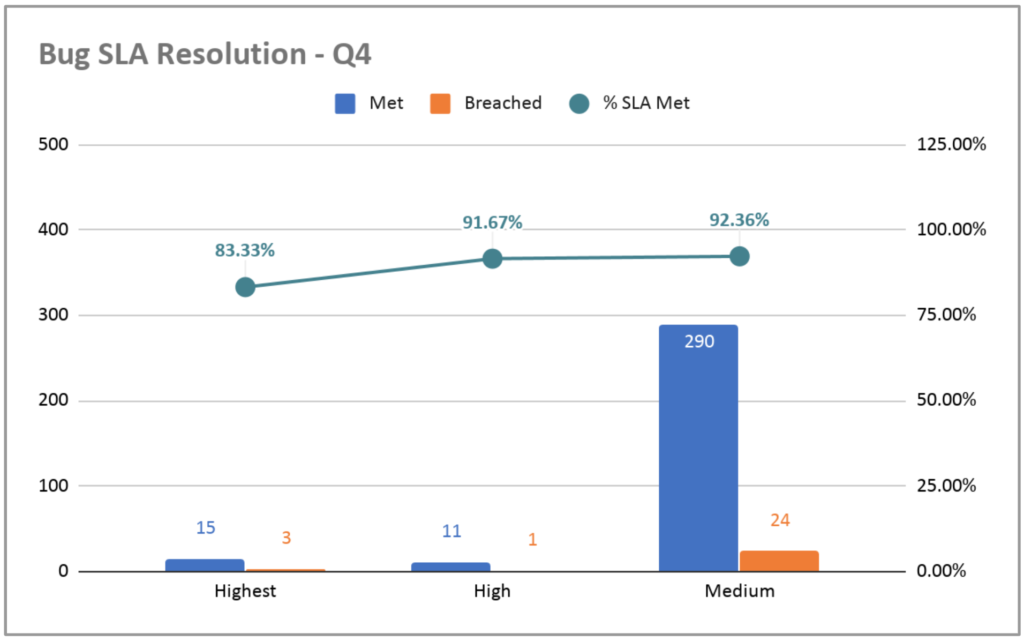
This is not the ideal way of viewing this info because it shows only an image of the moment, and not an evolution. To understand the evolution of any metric, you need to see how it did at different points in time.
As soon as I joined Lopes, I started bringing this topic up for discussion with the teams. One of the things we noticed is that 50% of deployed items were bug fixes. I was informed that “these bugs were caught before going into production, which is a good thing”. In fact, it is a good thing that these bugs did not reach the production environment and appeared to our users. However, they reached pre-production and needed to be corrected. Wouldn’t it be better if these errors didn’t even exist, not even in pre-production?
The OKRs we defined to help us with the quality theme were 3 additional KRs in order to Increase the cadence of deploys in production that I mentioned in the previous chapter:
- KR: Reduce the number of new bugs to 5% in pre-production.
- KR: Reduce the number of total bugs to 10% in pre-production.
- KR: Keep the number of total bugs below 5% in production.
And we add the following OKR:
- Objective: To improve the quality of the deliveries to the squads.
- KR: Review 100% of new stories to find poorly defined and / or ambiguous requirements.
- KR: Perform a 25% review of the Pull Requests of the squads.
- KR: Measure the Pull Requests volume of the squads.
Another example of bug tracking
At Conta Azul, we doubled the product development team in a period of 8 months between November 2017 and July 2018. This growth was aimed at increasing the team’s productive capacity.
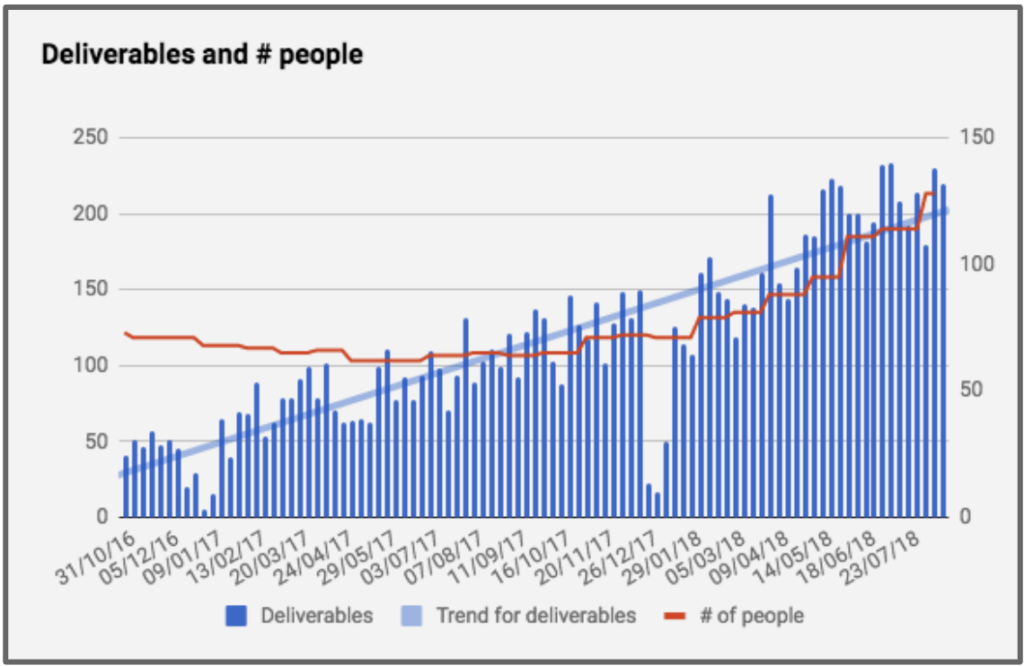
In addition, we divided the quantity of deliveries by the total number of people on the team to assess whether we were managing to increase our productivity individually.
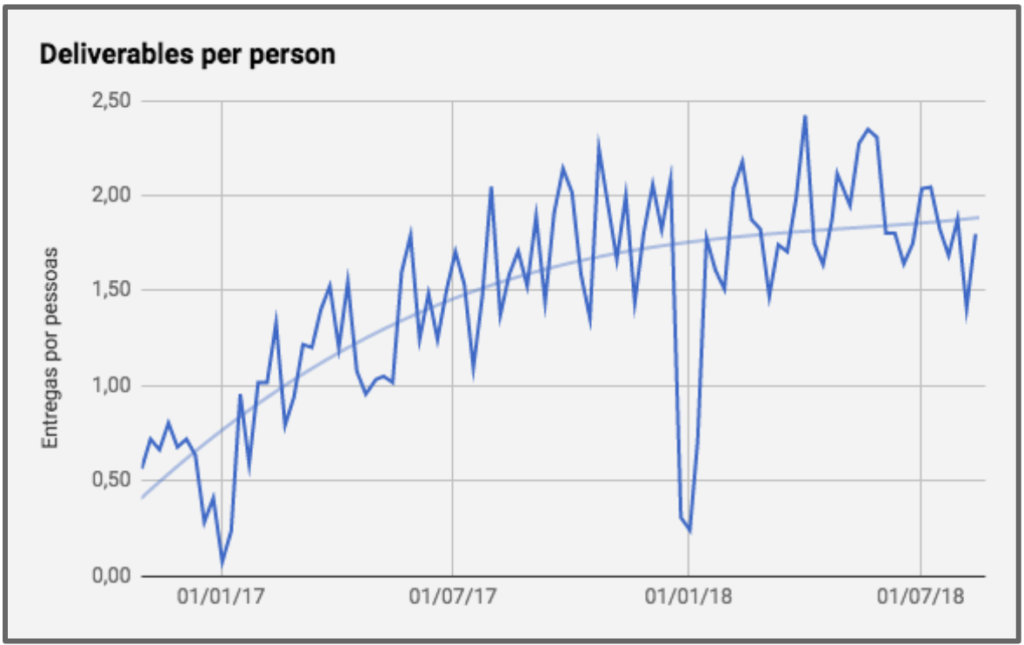
However, with the increase of people on the team, it ended up increasing the amount of bugs. So much so that the team that had already had 40% of its deliveries as a bug fix ended up having to increase this proportion to 60%. That is, despite having increased individual and total productivity, this increase in productivity was not being felt by the user, as it ended up being used for bug correction.
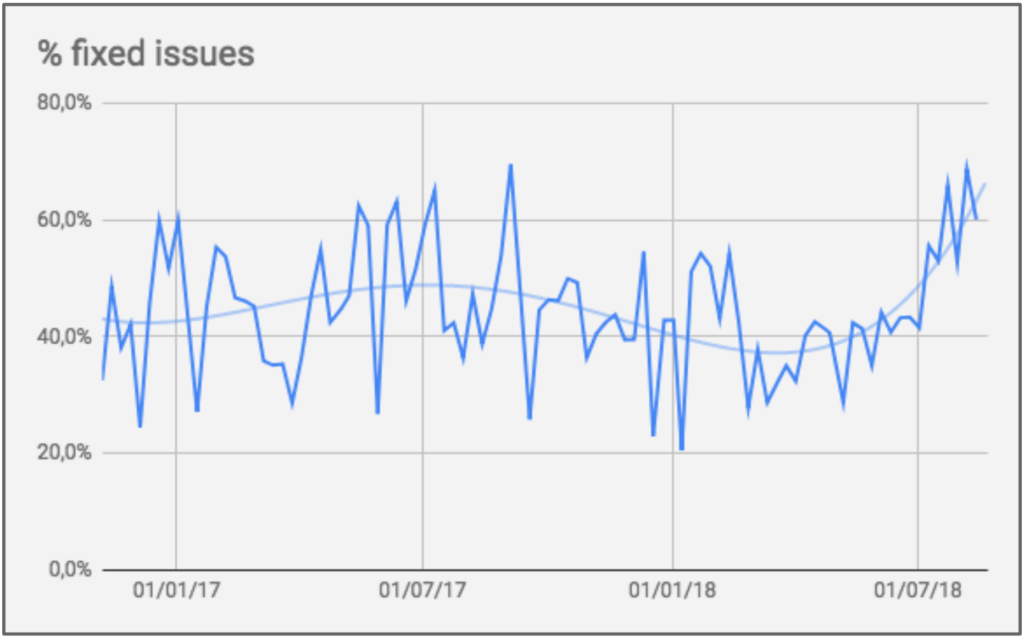
To control this problem, we increased our focus on fixing these bugs within the SLAs, which were:
- 85% of tickets resolved within 7 days
- 98% of tickets resolved within 30 days
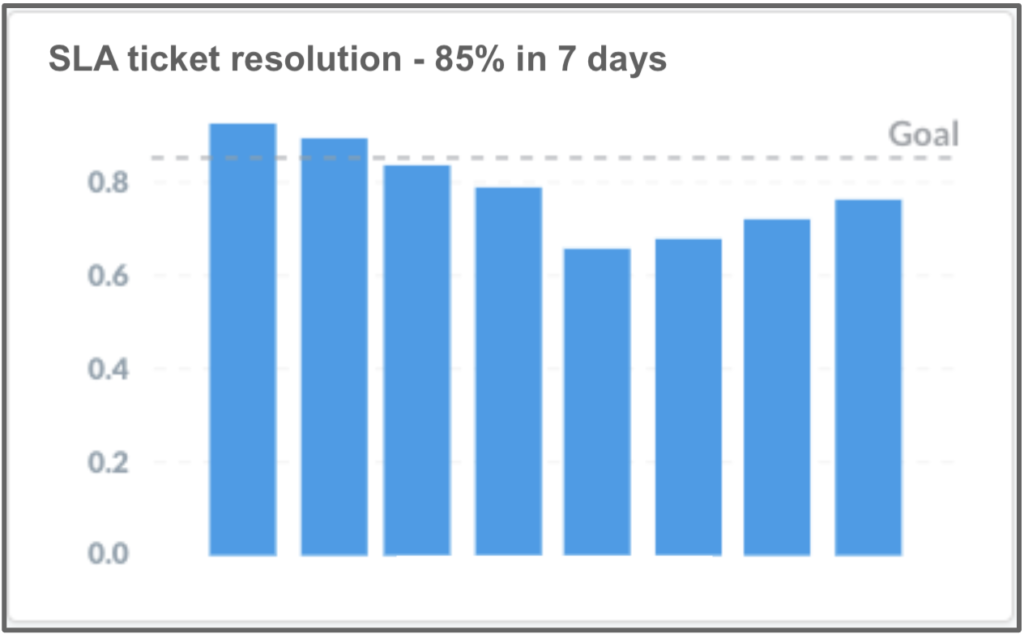
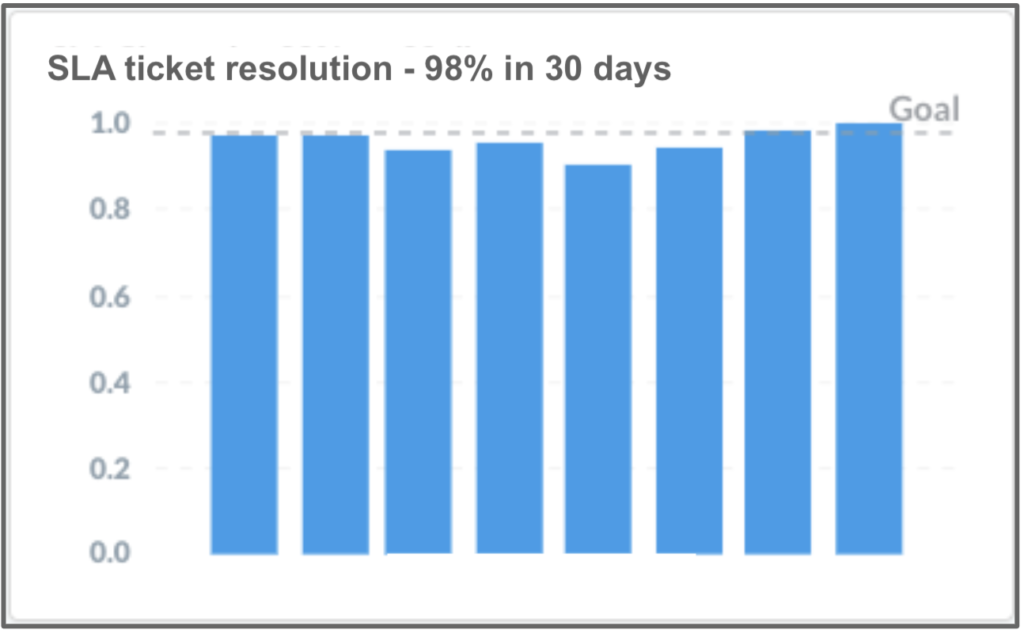
See that the quality has worsened and the customer suffered from it. But, after some time, we managed to return to the defined SLA levels. We looked at this metric weekly and, whenever we discussed this metric, we agreed that the best way to comply with the SLA was not to create bugs!
Quality is not just bug control
In addition to bug control, there are several other aspects that impact the quality of the digital product that we deliver to users. Performance, scalability, operability, monitorability are some examples of non-functional requirements.
When I joined Gympass, on my second Monday the system went down for users around 7 pm. I started asking people on the team what was going on and the answer was that Mondays are peak days in terms of gym visits and that the system could not handle the volume at all. As there was no monitoring, we were not alerted that the volume was higher than usual and we were unable to prepare properly. Two months later, when Rodrigo Rodrigues joined Gympass as CTO, he dubbed the event “Black Mondays”. To address the problem, we started to monitor and implement an infrastructure that could handle Monday peaks. And we set OKRs for uptime, successful HTTP requests and backend response time.
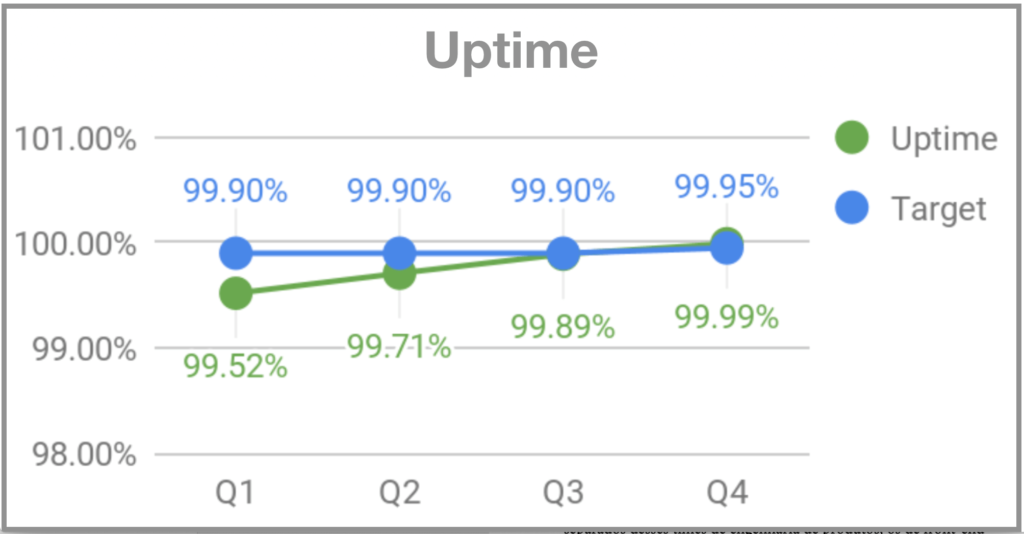
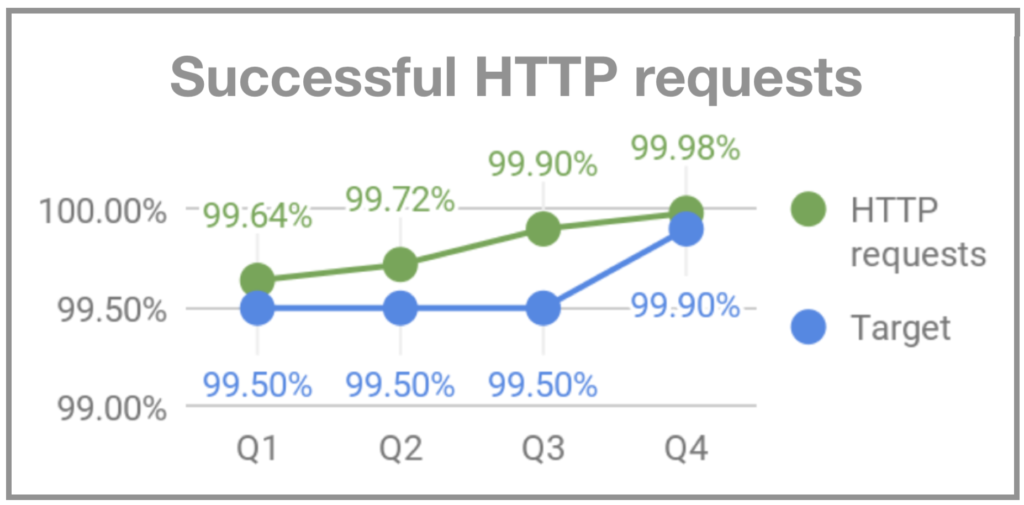
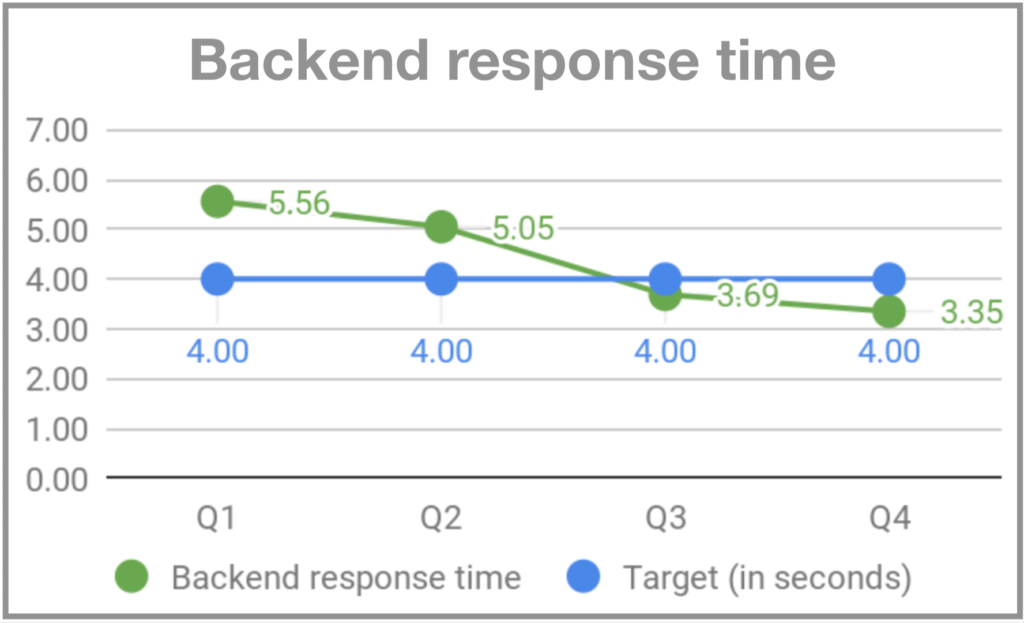
Why is quality so important?
Any user prefers to use a good quality product that behaves as expected. This is a sine qua non condition to provide a good user experience.
In addition to the user experience, there is another important aspect to consider when we talk about quality and bugs. Whenever someone needs to work on resolving a bug that was found in a digital product, that person needs to stop working on whatever they are currently working on in order to resolve the bug. This is an interruption in the workflow. If that person were able to deliver the software without that bug, they could continue to work on new things without interruption, which would make them more productive.
The relationship between productivity and quality
I had the opportunity to participate in an MIT course on how to create high-speed organizations. The course was taught by Professor Steven J. Spear, author of the book The High-Velocity Edge: How Market Leaders Leverage Operational Excellence to Beat the Competition. This is one of those very dense courses, full of content, but which can be summarized in one paragraph:
High-speed organizations are able to learn very quickly, especially with their failures, and to absorb that learning as an integral part of the organization’s knowledge.
A high-speed organization works by following the 4 steps ahead:
- Be prepared to capture knowledge and encounter problems in your operation.
- Understand and solve these problems to build new knowledge.
- Share the new knowledge with the entire organization.
- Lead to develop skills 1, 2 and 3.
The classic example is Toyota, with lean manufacturing and the concept of stopping production whenever there are failures, correcting them and using them as a learning opportunity so that they no longer happen. This ability to learn from failure is what gives Toyota the ability to stay ahead of its competitors for so long.
Another good example is Alcoa, which had a work incident rate of 2% per year, which was considered normal. Alcoa has more than 40,000 employees, so 2% of work incidents per year means that 800 employees per year have some type of work incident. This is a very impressive and worrying number.
To combat this problem, they implemented a zero error tolerance policy. Before implementing this policy, mistakes were seen as part of the job. Employees are now encouraged to report operational errors within 24 hours, propose solutions within 48 hours and report the solution found to their colleagues to ensure that knowledge spreads throughout the organization.
This caused the risk of incidents to drop from 2% to 0.07% per year! This reduction in the incident rate meant that fewer than 30 employees per year had any work incident problems after the zero error tolerance policy was implemented and Alcoa achieved an increase in productivity and quality similar to that of Toyota.
Fail fast vs. learn fast
An important factor in the Toyota and Alcoa examples is that recognizing and learning from failures must be part of the company’s culture. This is somewhat more common in the culture of technology companies, but not so common in traditional companies. During the MIT course I shared a table with a Brazilian executive from Grupo Globo, the major TV company in Brazil, a Spanish executive from AMC Networks International (Walking Dead, Breaking Bad and Mad Men), a German project manager living in Azerbaijan who works for Swire Pacific Offshore (oil and gas industry) and an MIT postdoctoral student in solar energy from Saudi Arabia.
All of my table mates were from more traditional industries. I was the only one at an internet company. The executives at Globo and AMC were there because they saw Netflix with its streaming video on demand and YouTube with its huge catalog of user-generated videos as major threats, stealing their audience very quickly and they wanted to understand how they could defend themselves.
Although the theme is somewhat obvious for internet companies, especially with the culture of technology startups that value fail fast. That’s what makes Netflix and YouTube a threat to traditional media companies like Grupo Globo and AMC Networks. However, even though this is part of the culture of internet companies, sitting and discussing it with people from more traditional companies was a great opportunity to reflect on the relationship between failure, failure recognition, learning and high speed:
- Recognizing the flaws and using the flaws as a learning opportunity must be well rooted in the organization’s culture. If people are not careful, as a company grows, it may lose the ability to accept failures as learning opportunities. It is very common for companies, as they grow, to become more and more averse to failure and to create a culture that ultimately encourages people to hide mistakes and failures.
- Another important aspect of learning from failures is to make this process a company standard. There is no point in failing, acknowledging the error, stating that you will no longer make that mistake and, some time later, making it again. This learning process with failures must be part of the company’s culture. Whenever a fault is identified, learning should happen as quickly as possible to prevent it from happening again. If the same failure happens again, something is broken in the learning process with the failure.
- Even in Internet companies, I realize that learning from failures is more common in the product development team, as retrospectives and continuous learning are part of the culture of agile software development. In other areas of the company, learning from failures is less common. This ability to systematize learning from failure must permeate the entire company.
Even though we hear a lot about the culture of internet companies to fail fast, talking about failing fast diverts our focus from what is really important, learning fast. We must put our energy into learning, not into failure itself. It is the learning process that makes people and companies evolve. And it is the ability of an organization to learn fast, especially with its failures, that will allow it to move at really high speeds.
Summing up
- Questioning whether or not product development should have a dedicated QA team is not the right question.
- The problem you are trying to solve is how to improve the quality of your product.
- A good quality proxy metric is the bugs. Bug inventory, new bugs per week and bug resolution SLA.
- A product development team must have all its members following these metrics and taking action to improve them.
- Managing bugs is not enough to manage the quality of the digital product. Performance, scalability, operability, monitorability are some examples of non-functional requirements that directly impact the quality of the digital product.
- Quality is at the forefront to provide a good user experience. In addition, it is essential to increase the speed of your product development team. The less bugs a team has to fix, the more time it has to focus on new things.
- High-speed organizations are able to learn very quickly, especially with their failures, and to absorb that learning as an integral part of the organization’s knowledge.
In the next chapter we’ll see a little more about metrics.
Digital Product Management Books
Do you work with digital products? Do you want to know more about how to manage a digital product to increase its chances of success, solve its user’s problems and achieve the company objectives? Check out my Digital Product Management bundle with my 3 books where I share what I learned during my almost 30 years of experience in creating and managing digital products:
- Startup Guide: How startups and established companies can create profitable digital products
- Product Management: How to increase the chances of success of your digital product
- Leading Product Development: The art and science of managing product teams
